
Beyond IBC
ZK Light Clients, Verkle Trees and connecting IBC to non-Cosmos chains -- the future of Interchain bridging with native IBC support.

As may have been clear by going over some of our previous research pieces we are believers in the modular blockchain and application-specific blockchain design paradigm. A consequence of this is that we envision a world with a lot of different blockchains, for various applications, verticals and so on. We are convinced that there will be a wide variety of blockchains and that those will grow as the number of applications gaining traction grows.
An inevitable result of more blockchains, either in the shape of a rollup or otherwise, is that interoperability will become exponentially more important. So as the world becomes more and more modular we expect to see a plethora of bridges pop up. One of the more exciting ones we see is Polymer. We will dive into how they are bringing IBC to all ecosystems below.
IBC
As a slight refresher, here is part of a section of a previous article by us, on IBC.
Inter-Blockchain Communication(IBC) is at its core a cross-chain messaging protocol for homogenous blockchains. This means that it connects chains that share similar functionalities, in this case, instant finality provided by the Tendermint consensus algorithm and ones that have light client functionality. The way IBC works is that two chains that are interested in having a connection with one another will put up a governance proposal on the destination chain. This is usually, to begin with, either through the Cosmos Hub or Osmosis (Currently Osmosis has 45 peers, and Cosmos 40). This means that there’s an agreement on a protocol level, and as such, there is no need for a trusted third party in an external bridge.
These two chains then require a light client on each other’s chain to cryptographically verify consensus state between the two chains, as well as a relayer to relay information between the light clients on the two chains. The relayers are required for liveness - the ability to be able to exchange messages among nodes, with the nodes successfully coming to a consensus. Let’s explore how this looks in practice:

This means that the trust assumption lies within the two validator sets of the connected blockchains, as such there are much fewer trust assumptions than other types of bridges and messaging protocols. For example, with XCMP in the Polkadot ecosystem, the trust assumption lies solely with the relay chain (Polkadot).
To show just how compatible and widespread IBC has become in the Cosmos ecosystem, and how many chains it connects - let’s take a look at a map of the current live connections.

With IBC there are two connotations that are important to note. Those two are connections and channels:
A connection is two stateful objects on two separate chains - the IBC module in the CosmosSDK.
A channel is a specific connection to a chain/app and provides message delivery info such as ordering, this is what is referred to the relayer.
ICS
ICS stands for Interchain Standard and sets parameters for transactions happening between chains using IBC. ICSs are basically module specifications for IBC transactions. For two chains to communicate using IBC they’re required to possess the same ICS specifications. One of the more interesting and unique ICSs is ICS-27, also known as Interchain Accounts.
Polymer will be supporting existing ICSs. As such, chains that are connected to Polymer will be able to take advantage of much of the great work being done by the wider IBC community of which Polymer has been a long time contributor.
Light Clients
Light clients are an essential part of blockchains. In their current form, they enable the ability for less hardware-intensive machines to participate in the verification process of blockchains and also help facilitate connections to others. They do so by only downloading the block header instead of an entire block. They trust honest full nodes to provide accurate information and hence are not trustless. There are several types of light client implementations, and one could even say that the rollup bridge contracts on Ethereum function akin to how light clients function for IBC-connected blockchains in the Cosmos ecosystem.
Light clients notably came into the spotlight with the emergence of the Cosmos ecosystem, and have gained significant popularity in regard to the possibilities it allows for in respect to scaling functions of blockchains. Here we're referring to how Celestia is utilising light clients to participate in data availability sampling to scale with the number of nodes in the network. This would allow light clients to have almost similar trust assumptions as full nodes while still not being required to download the entire block. This results in light clients, and consequently end-users, becoming first-class citizens of the networks they inhabit.
In most primordial monolithic blockchains, users are required to run a full node, where they'd have to store the entirety of the blockchain data if they'd like to participate in verification. This puts a hurdle on decentralization since as the scale and history of the blockchain grows, so increases the hardware requirements for full nodes. This problem is often referred to as state bloat. With light clients, as long as they're connected to an honest full node they're able to participate by scanning block headers, instead of entire blocks as with full nodes. A block header is a section in a block that serves as a summary of the rest of the block - such as the time and difficulty of when the block was mined, and the root of included transactions.

Light clients are used in bridging to facilitate the possibility for two bridging chains to verify the state of each other through the help of an off-chain relayer. By verifying each other's state machines the two connected chains are able to reach finality between each other on a protocol level. In the current setup of light clients, this does mean there is a certain level of trust involved, as just explained. In IBC the connection between chains is set up with a light client on each chain to verify the state of the chain.
The relayer builds transactions based on the state of the connected chains which are then submitted to the other nodes in the network. With IBC this is done via the Hermes relayer implementation. Some work is being done on the incentivisation of relayers to enable further decentralization and security. Currently, relayers are run manually and many are run by various validators that also run full nodes on connected chains, often enabling them to profit heavily from interchain MEV. There is ongoing relayer incentivization work to alleviate some of the issues this brings, which Polymer is also taking an active role in.
Light Client Block Verification in Tendermint is as follows;

Keep in mind that this is a simplified picture of the relationship between a full node and a light client. In actuality, many nodes participate in the peer-to-peer network.
ZK Light Clients
So, light clients are clearly a great invention, but how can we make them even greater? In Polymer's case, they're making use of ZK light clients, a new invention. ZK light clients will allow for increasing trust minimization and efficiency of transactions. By utilising ZK proofs it is possible to encode light client verification logic into circuits that will allow for making verification of batches of block headers more efficient. We covered block headers briefly earlier on, but something important to note is that also present in block headers are the previous block(s)’s hashes, which is what allows us to create the “chain” of blocks. In essence, the block header contains any data that isn’t the list of raw metadata itself.
A great example of the efficiency of light clients is that assuming your blockchain had 10.000 1MB blocks, you would be consuming 10GB of space on each full node (for the simplicity of the example, we are leaving out techniques such as data pruning etc). However, by just using block headers for those same blocks, you'd take up an order of magnitude less space. This is further increased by utilising ZK proofs, and their recursive nature. What's vital is that they allow for devices with less resources to perform validation and for blockchains that support light clients to read the state of another.
With recursive zk proofs, it is possible to increase the efficiency of the relay process and use even less space. Recursive zk proofs are when you take multiple proofs that are then aggregated into a single proof. The single proof is only valid if all inherent proofs are valid, and it is much easier to verify and less costly. This is especially appealing when proofs are verified on-chain. Thousands of proofs can be compressed into a single proof, saving enormous costs in the verification process. This is because a recursive zk proof proves the existence of a previous valid proof. Since the verification is a computation itself, it can be expressed in a circuit. A single proof on this computation/circuit certifies the validity of an inner proof, which may include another proof and so on and so forth.
Another reason for wanting recursive ZK snarks for on-chain verification, is that running a Tendermint “light client” on Ethereum is quite expensive, as you'll see throughout this article. Even if it is optimised, the actual cost of verification is expensive. If you were going to just verify Tendermint light client verification logic on Ethereum, it would even be possible to exceed the block gas limit. Recursively verifying ZKPs will allow for a much simpler on-chain verification process.
The reason for wanting recursive proofs to verify block headers is to generate several proofs in parallel and then recursively proof them together. This means that the usual cost of verifying a single block header of which there may only be a single cross-chain transaction can be recursively lowered in parallel. This also means that you now just verify the proof of validity on-chain instead of the entire block header. Similarly to how we achieve scalability with ZK-rollups.

The actual on-chain header verification will be happening under the secp256k1 elliptic curve parameters (for now, but there are other curves that are possible to use as well) with the ECDSA algorithm. secp256k1 was constructed in a systematic way which allows for especially efficient computation. As a result, it is often more than 30% faster than other curves if the implementation is sufficiently optimized. Secp256k1 curves are both used in Bitcoin and Ethereum. However, it is not the most SNARK friendly, and as such other curves will be researched as well.

One thing to note is that the general calldata of all the transactions and their Merkle tree still need to be stored. We will get into how this can be made more efficient in the next section. If you're interested in reading a bit more into the reasoning behind the implementation of ZK light clients and IBC logic with ZK proofs in general, then I recommend that you head over and read the newly released Polymer article, which covers parts of these questions.
References
https://github.com/tendermint/tendermint/blob/v0.34.x/spec/core/data_structures.md
https://docs.rs/tendermint/0.23.7/tendermint/block/index.html
https://www.researchgate.net/publication/344663049_A_Tendermint_Light_Client
https://github.com/0xPolygonHermez/pil-stark/blob/main/circuits.bn128/stark_verifier.circom.ejs
Verkle Trees
Verkle trees are a more efficient data structure for state commitments. The benefit here is that it allows you to have reduced proof sizes and verification costs on-chain for proofs. In general what Merkle/Verkle trees bring is the ability to make sure that the binding of data is identical down to the very last byte, which allows us to provide finality agreements to blockchain nodes.
To understand how Verkle trees are different from Merkle trees, it is important to first understand the latter. Merkle and Verkle trees are quite similar in structure but have a few components that make them quite different as data structures for state commitments.
In a Tendermint/CosmosSDK structure, Merkle trees are used to share transaction data between nodes, in particular between full nodes and light nodes for the light node to verify a certain block. In this situation, the light node gets a commitment from the full node and gets the witness which enables the light client to construct the root in the block header.
In Ethereum, Merkle trees are used in the Execution layer in which block headers consist of 3 roots of Merkle trees. These are the state root, the transaction root and the receipt root.
There is also the Ethereum global state tree that updates over time, and as a result, also increases in size as time goes on. This is one of the reasons why Ethereum is also exploring the use of Verkle tress in future releases to minimize the amount of state that Ethereum full nodes are required to hold. This is what is referred to as statelessness (weak), which we will touch on a bit later on. This similarly also cements why light client compatibility is so vital for blockchains, and why Ethereum is also looking to add them in the future since it enables clients that have lesser hardware to be able to verify the blockchain itself. The state bloat issue is also why history expiry is needed with the added amount of calldata (transaction data) that is coming as a result of EIP-4844. In general, state bloat is a massive issue for blockchains if you're not interested or willing to increase the hardware requirements of nodes, as it hinders decentralisation. There are various ways to mitigate this, and one of them is Verkle trees.
Let's take a look at how Merkle trees look on paper, which will then enable us to later see how they differ from Verkle trees.

The witnesses in Merkle trees have the size of lgxN(x-1). In a Merkle tree, the proof is the entire set of nodes in the tree that share a parent with nodes in the path down to the node being proven. This means that you have to include a lot of nodes in the witness that will allow you to prove a commitment. This of course grows exponentially in very big trees since the top of the tree that you need to prove would grow very large as well.
The main difference between Merkle and Verkle trees lies in how they structure their witnesses and as a result their sizes. Before we look at the structure of Verkle Trees, let us detail how witnesses work in them. First off, what's important to note is that to all positives, there are tradeoffs. In the case of Verkle trees, by moving to a witness size of lgxN(2) you lose on compute efficiency. However, it enables us to reduce the proof size and as such also lowers the verification cost on-chain for proofs. This is especially vital if you're trying to bridge to and from Ethereum, where gas cost, for now, is quite high. A great example of just how expensive on-chain proofs are for bridging on Ethereum, take a look at the test calculations that Electron Labs did for their "ZK IBC" idea. To lower cost, verkle trees and recursive proofs can help immensely alongside many of the other scalability solutions in the works for Ethereum as a whole.
In Verkle trees, instead of needing to provide all the nodes that share a parent, you instead only have to provide the path to the root. So in a very wide tree, the path will be quite small compared to all the sister nodes (witnesses) that would have to be provided in a Merkle tree commitment. Another added commitment that is needed alongside the path in Verkle trees is vector commitments (polynomial, which can create a proof for any point, refer back to the curves further up if you want a refresher on points), which replaces the functionality of the sister nodes in Merkle trees. This means that they give verification that a certain child node (the node under the parent) is actually the correct node in the tree, while only providing the path itself.

No sister nodes are required in proof construction in the tree. You just give the path itself plus a few short proofs to link each commitment in the path to the next.
If you're interested in learning exactly how the Verkle trees are constructed in Polymer, then we highly recommend that you check out their brilliant presentation on the internals of Verkle trees presented in a visual way - link. In the beginning, Polymer won't be using Verkle trees. However, in the future as a result of state bloat and proof verification pricing, it makes sense to make the switch. As such, Polymer is preparing for the future.
Beyond the basic functionality of Verkle trees and polynomial commitments, we can add even further optimisations that can allow for a myriad of other incredible future implementations. Let's cover them briefly:
These optimisations come through properties that polynomial commitments enable. Primarily the ability to make fixed-size proofs that link the nodes in the path for any length or path. This is done through a deterministic source of randomness for non-interactive proofs via Fiat Shamir Heuristics(FSH). FSH enables us to implement multiproofs through random evaluation. This is also where the trade-off between Merkle and Verkle trees comes in - the proof generation of computing a polynomial. This single polynomial proof can then act to prove the correct path(s).
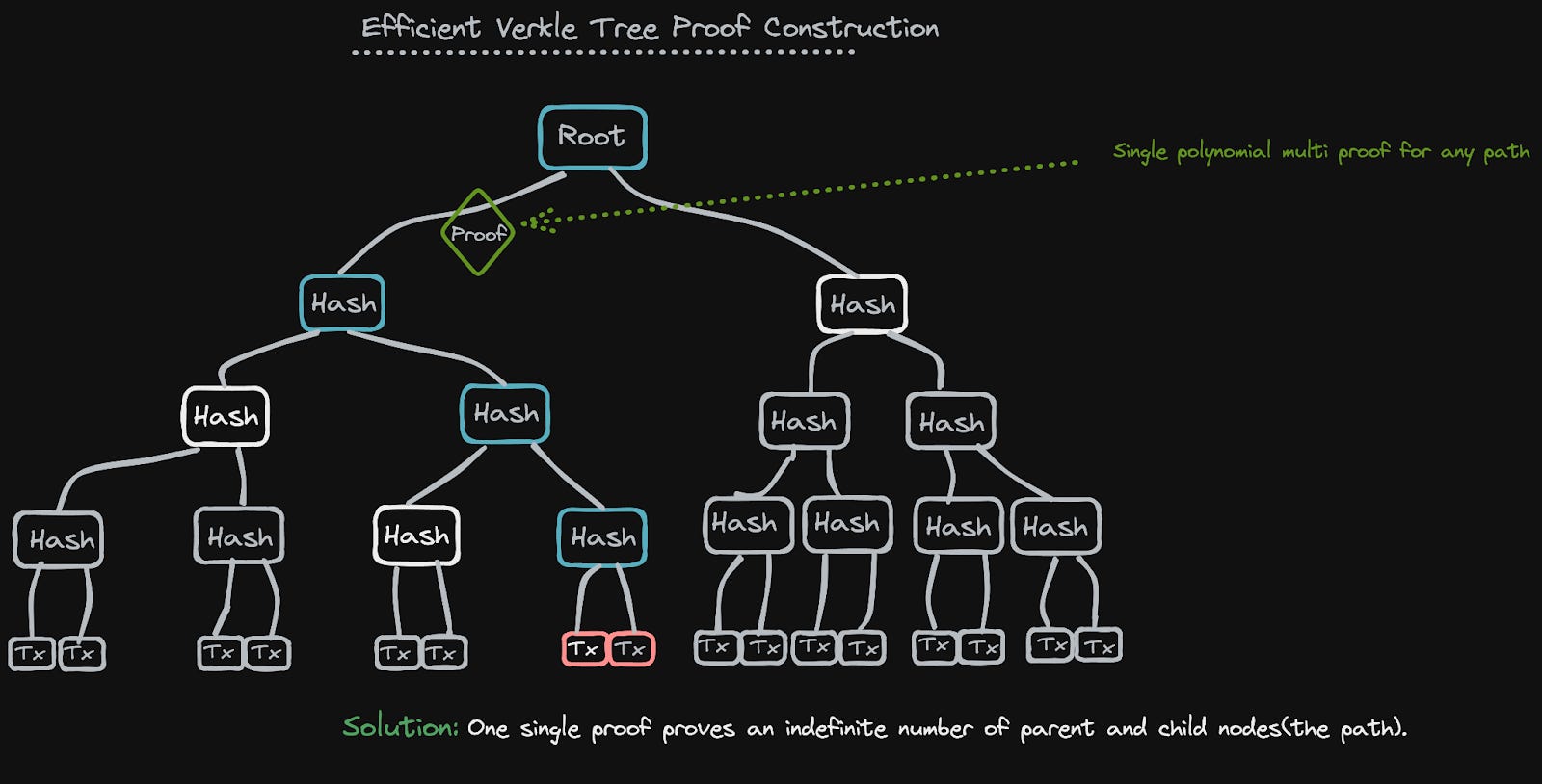
If you're interested in digging deeper into how single efficient multiproofs are achieved we highly recommend you check out the great Dankrad's article on them.
The implementation of Verkle trees is going to allow for some quite unique and interesting functionalities that can aid in both the scalability and decentralization of blockchains. Let's take a look at statelessness in particular and also touch slightly on another method, namely state rent. Both of these are methods to alleviate the state bloat that all blockchains suffer from. As Vitalik notes in "a state expiry and statelessness roadmap" from around a year ago "The Ethereum state size is growing quickly. It is currently around 35 GB for just the state and over 100 GB including all Merkle proofs, and is increasing by roughly half that amount per year."
Statelessness or weak statelessness is the concept of only requiring block proposers to store state, and then having other nodes in the network verify the block without having to hold and store the state of the blockchain. This is something that requires Verkle trees and multiproofs, which will enable clients to verify the global state, without actually holding any state themselves. Another added feature that is planned to be added alongside weak statelessness on Ethereum is state expiry, which we touched on earlier. With state expiry, the state still needs to go somewhere. This could either be on archival nodes, or we could also utilise a method referred to as state rent.
State rent is the concept of "renting" out state to be stored and having proof of accessibility of it on other chains or within specific nodes on the chain itself. There are various projects working on solutions that could allow for this, for example, Laconic, but the way Polymer is structured you could also envision a world where Polymer is used for state rent as well. There is also a method for which you could disperse state with provable retrievability. Joachim Neu presented a very interesting paper on this during the Modular Summit, which we enjoyed co-hosting with Celestia. If you want to learn more, you can read the paper [here].
References
https://docs.google.com/presentation/d/1zv26gsBiU-xsepXnrpmcBIFVP49QN9jvbbcI_AZKssA/edit?pli=1
https://dankradfeist.de/ethereum/2021/06/18/verkle-trie-for-eth1.html
https://ethereum-magicians.org/t/proposed-verkle-tree-scheme-for-ethereum-state/5805
https://beamstart.com/news/merkle-trees-vs-verkle-trees-16609184619683
IBC in Solidity on Ethereum and beyond with recursive snarks
Something that has been researched by several teams lately is how to bring IBC to Ethereum before it adds light client compatibility. For example, Electron Labs has presented a "version" of IBC where they have a smart contract on Ethereum act as an on-chain light client (which IBC requires). This is similar to how bridge/rollup contracts work for Ethereum rollups. However, the problem with this is that you're essentially trusting a smart contract (which is often upgradeable or controlled by a centralized team) which obviously doesn't allow for trust-minimized bridging on a protocol level where the trust lies in the two validator sets of the two chains connected. The beauty of IBC on Tendermint/CosmosSDK chains is that they have light client support built in and that it enables chains to agree on a protocol level to open up a connection between them in a trust-minimized way. For now Electron Labs only have a circuit for ed25519 signature verification and not the actual light client logic. To enable the smart contract to act as a light client with IBC logic, they would need to make other necessary changes.
So how is Polymer planning on providing IBC in the Ethereum ecosystem, incl. rollups. Let's dig into Polymer's GitHub to look at the work they've done so far.
Currently, the best way to implement IBC in a way, so that it functions on Ethereum, is to implement a ZK-IBC structure. Here validity proofs are verified on-chain proving the validity of a transaction that has been done on a connected chain. As mentioned earlier, Electron Labs have a great blog post on how this can be achieved as well, but there are a few things that I do feel are important to note. The IBC modules need to be converted to solidity so that IBC transactions can be verified properly + we also need a solidity verifier for Plonky2 (which is currently the fastest proving system for recursive snarks - which is one of the things we need for an efficient implementation of zkIBC). If you're interested in following along with the development of the Plonky2 verifier that Polymer is doing, I highly recommend you check their GitHub
Presently, Polymer has already created smart contracts on devnets that acts as on-chain light clients for both Ethereum and BSC. This enables the smart contracts to receive IBC packets since they have rewritten the IBC modules in Solidity. Likewise, Polymer has also done testing for a variety of other EVM-compatible chains such as Binance, Avalanche, Fantom, Polygon and also Solana.
References
Polymer
IBC e2e
In addition to standard IBC, Polymer will also feature a by-product called end-to-end IBC. This is an excellent fit for the way we view the modular world taking shape, as connected chains are considered to be "rollups” in this product. E2E IBCs are remote VMs that allow for native IBC and light client support. E2E IBC can be adopted by all chains, both application-specific, other L1s, L2s and various execution environments.
What this means is that connected chains can have their own “rollup” that works as a remote VM in which there is light client support and native IBC connections. As such, chains that usually aren't able to utilise light clients can have an environment where they can connect and use IBC logic, without actually implementing the modules themselves.
These remote VMs will interact via Polymer through interchain account smart contract APIs on Polymer itself. Through this, they're decoupling the networking layer that chains usually rely on, and instead allow the remote VMs to operate as an extension of Polymer itself that supports native IBC connections. This means that Polymer is able to maintain an IBC connection on behalf of connected chains.

The state of the E2E IBCs is going to be verified on Polymer, as is usual with rollups through light clients, which CosmosSDK and Tendermint support. On the Polymer side, there will exist IBC smart contracts (also sometimes referred to as bridge contracts on Ethereum). These will handle movement from Polymer to the non-IBC chain. The native light client support means that trust minimization can easily be achieved.
Polymer will also feature what they call xApps, which will function as multichain applications in rollup form on top of Polymer. This will give them immediate access to a wide variety of chains on which to settle and handle transactions.
The Polymer Thesis
Polymer is making use of existing Cosmos technology by utilising IBC to their advantage by building a universal IBC routing protocol that will enable end-to-end IBC connections and channels between non-Tendermint chains such as Layer 1s and even rollups on top of these layer 1s. Polymer is also taking a modular approach to building out its networking protocol so that it is optimised in every part of the stack.
As such, they will enable IBC connectivity to all connected chains which will allow for native inter-chain composability for applications built on top of Polymer. The way Polymer will function is as a chain-agnostic IBC networking layer, they are doing this by decoupling the networking layer which will allow for rollup IBCs that function as data layers for application logic across various chains. This is enabled by using light clients which IBC is reliant on with added security and verification logic by using ZK light clients to allow for encoding verification logic into a circuit, making verification of batches of block headers more efficient.
The e2e IBCs are integrations to remote VMs in a way that allows for the decoupling of the IBC layer from Polymer connected chains. This is done through publishing batched commitments through Merkle/Verkle trees to rollup chain contracts. The verification time and proof sizes will be reduced by enabling Verkle trees in the fturue, which are an “upgrade” to Merkle trees that allow for much smaller witnesses.
Polymer will consequently maintain IBC connections and channels on behalf of connected chains, which can virtually function as multi-chain IBC rollups with the applications that can be built on top. This should also allow for interchain accounts across non-native Cosmos chains.
Polymer has also partnered up with Celestia to become the bridging provider between Optimistic Rollups built on top of Celestia through an Optimistic light client implementation of IBC. Read more here.
If this sounds interesting to you, and if you'd like to work on problems plaguing blockchains, then Polymer is hiring - check out their job listings here.
Its Friday night and I'm sitting here reading this article with a drink in my hand. First off, this article is intense. Secondly, what a time to be alive. I'm very excited for the next 5-10 years to see where we land with IBC, ZK proofs, and Web 3.0. I selfishly hope I'm throwing down my bets for a winning hand. In the meantime, I raise my glass and wish everyone the reads this the best of fortune for themselves and their families.
PS - This type of long form analysis is something that adds a lot of value when compared to Twitter or Reddit or Telegram or Discord. Keep at it! Also, like I'm trying to game tonight and you have me opening all these connected articles and google presentations and stuff...
It was a great an in-depth read! Very much enjoyed it! Also, I'm amazed how you can produce such articles on weekly basis :D